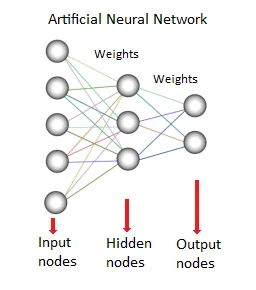
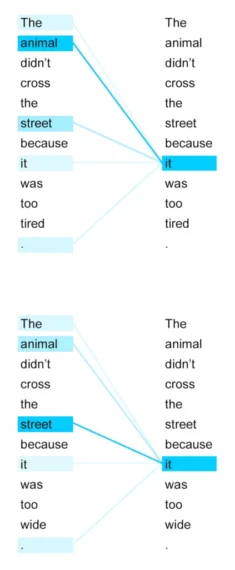
What is artificial intelligence?
There was an exchange on Twitter a while back where someone said, ‘What is artificial intelligence?’ And someone else said, ‘A poor choice of words in 1954’.
— Ted Chiang, “The machines we have now are not conscious”, Financial Times
Artificial intelligence (AI) is formally defined as the branch of computer science focused on systems capable of performing tasks that typically require human intelligence, such as reasoning, decision-making, and problem-solving. Unfortunately, defining a technology by the types of problems it solves is vague and not particularly helpful. For instance:
- If you build a sophisticated spreadsheet model that analyzes data and generates a prediction, have you created AI?
- If a grammar checker claims to use AI but is built with traditional programming techniques rather than modern AI approaches, should you consider it artificial intelligence?
In one sense, the label “AI” doesn’t matter. If a tool solves a problem, who cares what technical architecture it was built on? On the other hand, creating a strategy to turn a groundbreaking new technology into measurable business outcomes requires understanding the basics of how the technology works to help you decipher both what it is good at and how to use it more effectively.
 Beyond being vague, the term “artificial intelligence” is problematic because it reinforces the myth that AI systems understand what they’re doing. Even today’s advanced architectures do statistical calculations on data, not reasoning as a human would. To understand the distinction between computation and comprehension, consider John Searle’s famous 1980 thought experiment, the “Chinese Room Argument”:
Beyond being vague, the term “artificial intelligence” is problematic because it reinforces the myth that AI systems understand what they’re doing. Even today’s advanced architectures do statistical calculations on data, not reasoning as a human would. To understand the distinction between computation and comprehension, consider John Searle’s famous 1980 thought experiment, the “Chinese Room Argument”:
Searle imagines himself alone in a room following a computer program [rules] for responding to Chinese characters slipped under the door. Searle understands nothing of Chinese, and yet, by following the program for manipulating symbols and numerals just as a computer does, he sends appropriate strings of Chinese characters back out under the door, and this leads those outside to mistakenly suppose there is a Chinese speaker in the room.
— “The Chinese Room Argument”, Stanford Encyclopedia of Philosophy
Searle makes language processing sound disarmingly simple: just follow the rules. But language in the wild is complex, context-sensitive, ambiguous, and ever-changing. In short, it defies rules. Processing language has always been one of the biggest challenges in computer science. That’s why language processing has become a benchmark for AI capability. And why recent breakthroughs in generative AI have gained so much attention.
The modern AI paradigm for language processing, Large Language Models (LLMs), yields a lot better results than previous approaches. However, LLMs still only mimic human reasoning by using probability to iteratively predict the next word in a string of text based on a complex analysis of all previous words.
Because AI has no way to check its prediction against real-world experience, its pattern-matching algorithm can occasionally produce errors (commonly referred to as hallucinations). Some errors are so obvious that even an elementary school student would immediately recognize them. We laugh at these. Other errors can sound surprisingly convincing, even to those with domain expertise. LLMs have even been known to make up quotes, citations, or other evidence to support their erroneous conclusions. That’s why using LLMs without understanding and mitigating the risks inherent in how they work can be catastrophic.
Key AI concepts
Before we look more specifically at how various AI architectures work, it’s important to grasp a few core AI concepts. In addition to making the difference in AI architectures easier to understand, you will see these concepts pop up frequently in AI articles and discussions. Understanding them will help your AI knowledge progress faster.
Tokens
Modern AI architectures break their training data into small, unique numerical representations called tokens. For language processing, a token can be a whole word, a part of a word, or even a symbol such as punctuation. For example, the word “tokenization” might be split into tokens like “token” and “ization”. Each model has a fixed vocabulary of these tokens that it can recognize and work with.
In simple explanations of AI language models, it’s common to substitute “word” for “token” because it’s intuitively easier to understand. I use this approach. Just remember that LLMs aren’t actually predicting the next word, they are predicting the next token.
Tokens aren’t limited to language processing. Other media can also be broken down into tokens for processing:
- Images: Patches of pixels
- Audio: Sound segments
- Video: Spatio-temporal segments
Feature engineering
In AI, features are specific, measurable characteristics of data that help make predictions or classifications. For example, in a house price prediction system, features might include square footage, location, and number of bedrooms. Feature engineering is the process of identifying these useful characteristics.
In early AI systems, humans had to manually identify and create these features. For image recognition, this meant explicitly telling the system to look for specific aspects like edges, colors, or shapes. Human feature engineering was time-consuming, required domain expertise, and was limited by human intuition about what features matter.
One of the most important breakthroughs of modern deep learning is its ability to automatically discover important features on its own. When shown millions of cat photos, a deep learning system builds up its understanding in layers: early layers might detect basic features like edges and textures, middle layers might combine these into patterns like whiskers or fur, and deeper layers might recognize complex concepts like ‘cat sleeping’ or ‘cat playing.’ Automatic feature engineering allows the system to discover subtle patterns that humans might not have thought to specify.
Modern AI often combines both automated feature learning where possible with human-engineered features where domain expertise adds value.
Structured vs unstructured data
Early AI systems could only work with structured data, meaning information that was carefully organized, cleaned, and labeled by humans. Imagine being handed a filing cabinet where every folder is perfectly labeled and organized versus a messy desk covered in random papers. Early AI could only handle the filing cabinet.
Today’s AI systems, particularly deep learning models, can work with unstructured data like natural language, images, or audio in their raw form. This is revolutionary because most of the world’s information exists in unstructured forms. However, there’s a trade-off. While modern AI can handle messier data, it needs massive amounts of it to learn effectively—think millions of examples rather than hundreds. This helps explain why companies with access to large amounts of data (like Google, Meta, or Amazon) have been at the forefront of AI development.
Prediction transparency
The evolution of AI represents a trade-off between power and transparency. With early AI, you could see how decisions were made because the system followed clear, human-written rules. Modern deep learning systems are more like black boxes. They make better decisions, but it’s much harder to understand exactly how they arrive at those decisions.
This trade-off has important implications for business use of AI. An AI system that can accurately predict which customers will churn—but can’t tell you why—might have value for revenue forecasting. However, it is of limited value if the goal is to find ways to improve customer retention. Sometimes organizations need to choose between a more powerful but opaque AI system and a simpler but more transparent one.
Deterministic vs probabilistic output
Computer technologies are generally deterministic. Like a calculator, they always give the same output for the same input. But generative AI is different.
Generative AI works by predicting what comes next based on patterns in their training data. For each decision (like choosing the next word), the model assigns probabilities to many possible options. For example, after “The cat sat on the…”, the model might think “mat” has a 30% chance of being next, “chair” has 20%, and so on.
Rather than always choosing the highest probability option, models use controlled randomness in their selections. This helps them generate more natural and varied responses while avoiding getting stuck in repetitive patterns or becoming too rigid in their outputs. But getting a different answer each time when using the same prompt makes some AI use cases quite challenging.
Programmers who create AI apps by calling a model’s API can directly control how variable the response is. Conservative settings heavily favor high-probability choices and produce more consistent, focused results. Higher variability settings result in the probability distribution being flattened, allowing lower probability options to be selected more frequently. This produces more diverse and creative outputs, but with potentially less precision.
You can’t explicitly set the variability of a model from a chatbot interface. However, you can use prompting techniques to tell the model how conservatively or creatively you want the model to respond. Some chatbots, such as Microsoft’s Copilot, have a separate “creative mode” designed to produce more varied output.
How AI works
AI has suddenly sprung into mainstream conversations. But it isn’t new. The term artificial intelligence was coined in the 1950s. And there was prior work that laid the foundations, even if AI hadn’t been named yet. That means researchers have been working on AI for at least 75 years.
AI architectures can be described using the analogy of a Russian nesting doll, with the broad term “artificial intelligence” being the outermost doll. Each architecture is a subset of the architectures above it. Therefore, all the terms shown accurately describe today’s generative AI. However, “deep learning” is the most specific and the most frequently used.